Abstract
Balancing competing objectives is omnipresent across science and engineering — drug efficacy versus toxicity, model accuracy versus latency, material strength versus weight. Multi-objective Bayesian optimization (MOBO) is the standard approach: fit a probabilistic surrogate to each objective, then optimize an acquisition function to select the next design. In practice, however, surrogate and acquisition choices rarely transfer across problems, and the per-step refitting and re-optimization overhead accumulates quickly in parallel or time-sensitive loops.
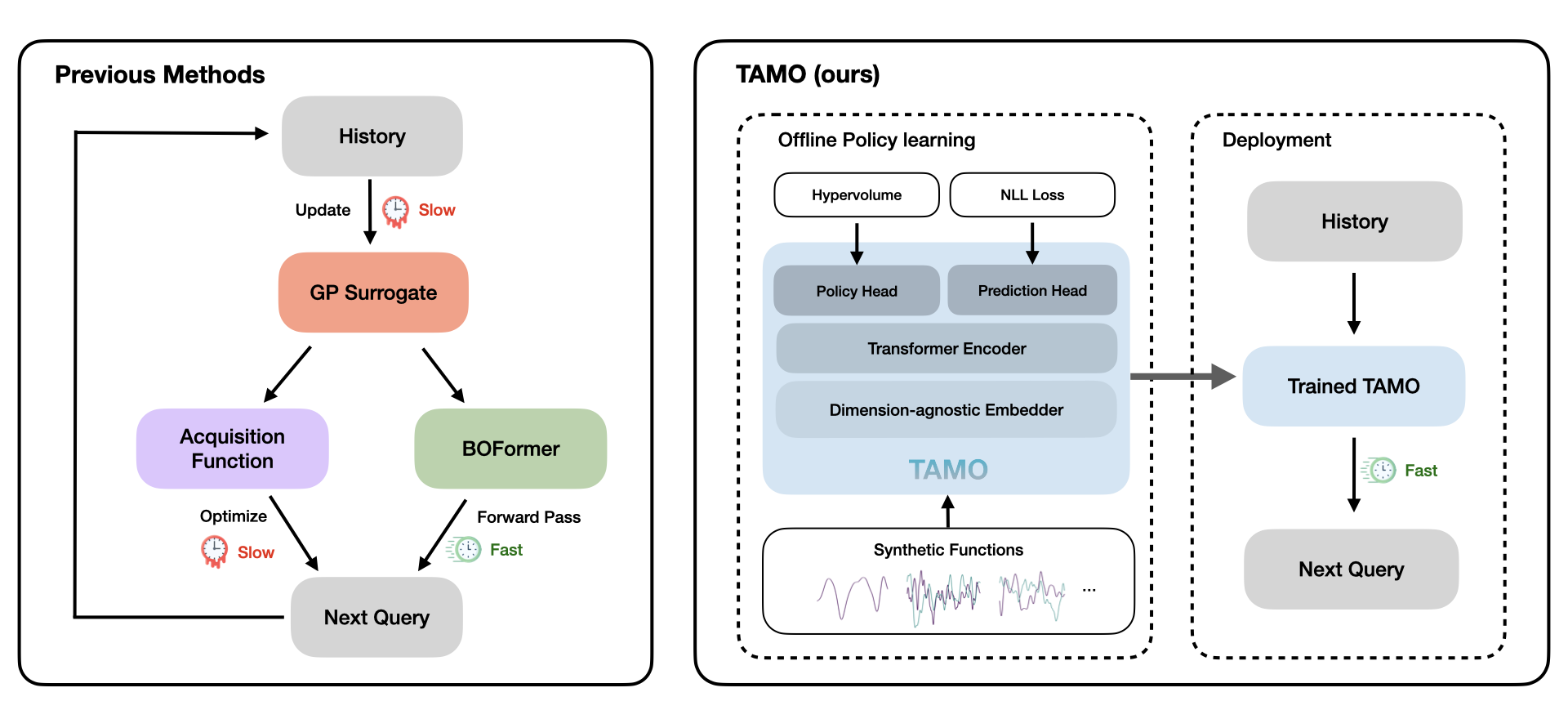
We present TAMO, a transformer that replaces the entire surrogate-plus-acquisition stack with a single forward pass. By operating directly over the optimization history — without fitting any task-specific model - TAMO can be pretrained once on diverse synthetic tasks and transferred to new problems in any input or objective dimensionality, with no retraining required.
Across synthetic benchmarks and real-world tasks, TAMO reduces proposal time by 50–1000× versus GP-based MOBO while matching or improving Pareto quality under tight evaluation budgets. These results demonstrate that in-context learning is a viable path toward plug-and-play multi-objective optimization — removing the need for per-task surrogate engineering without sacrificing solution quality.
Limitations of Classical MOBO
Real-world design problems rarely have a single number to maximize. The answer is not a single point but a Pareto front: the set of designs where no objective can be improved without hurting another. The goal of multi-objective optimization is to approximate this front with as few costly evaluations as possible.
To measure progress toward this front, we use the hypervolume (HV) indicator: for a reference point \(r \in \mathbb R^{d_y}\), \(\text{HV}(\mathcal{P}(\mathcal{X}) \mid r)\) measures how much of the objective space between \(r\) and the approximated frontier \(\mathcal{P}(\mathcal{X})\) is covered by Pareto-optimal points.
Classical MOBO refits a statistical surrogate — typically a Gaussian process (GP) — at every step and re-optimizes an acquisition function (AF). It works, but:
- The choice of surrogate and acquisition rarely transfers to the next problem.
- The per-step overhead from GP refitting and AF optimization scales quickly in parallel settings.
- Most acquisitions are myopic: they optimize a one-step gain, which can miss designs that open up better regions of the Pareto front later.
The question this paper asks is simple: what if a single pretrained model could replace both, for any problem, in any dimensionality?
TAMO: Task-Agnostic Amortized Multi-Objective Optimization
TAMO is a transformer-based framework trained on a large, diverse corpus of synthetic optimization tasks. At test time, it conditions on the optimization history and suggests the next query in a single forward pass.
| Method | Multi-objective | End-to-end amortized | Input agnostic | Output agnostic |
|---|---|---|---|---|
| Vanilla MOBO | ✓ | ✗ | — | — |
| BOFormer | ✓ | ✗ | — | ✗ |
| NAP | ✗ | ✓ | ✗ | ✗ |
| DANP | ✗ | ✗ | ✓ | ✗ |
| TAMO (ours) | ✓ | ✓ | ✓ | ✓ |
Architecture
The key enabling component is a dimension-agnostic embedder: each observation \((\mathbf{x}, \mathbf{y})\) - regardless of how many input features or objectives it has — is projected to a fixed-size vector by applying scalar-to-vector maps dimension-wise, interacting via attention, adding learnable positional tokens, and mean-pooling. This lets the same backbone process tasks with different \(d_x\) and \(d_y\) without any architectural changes.
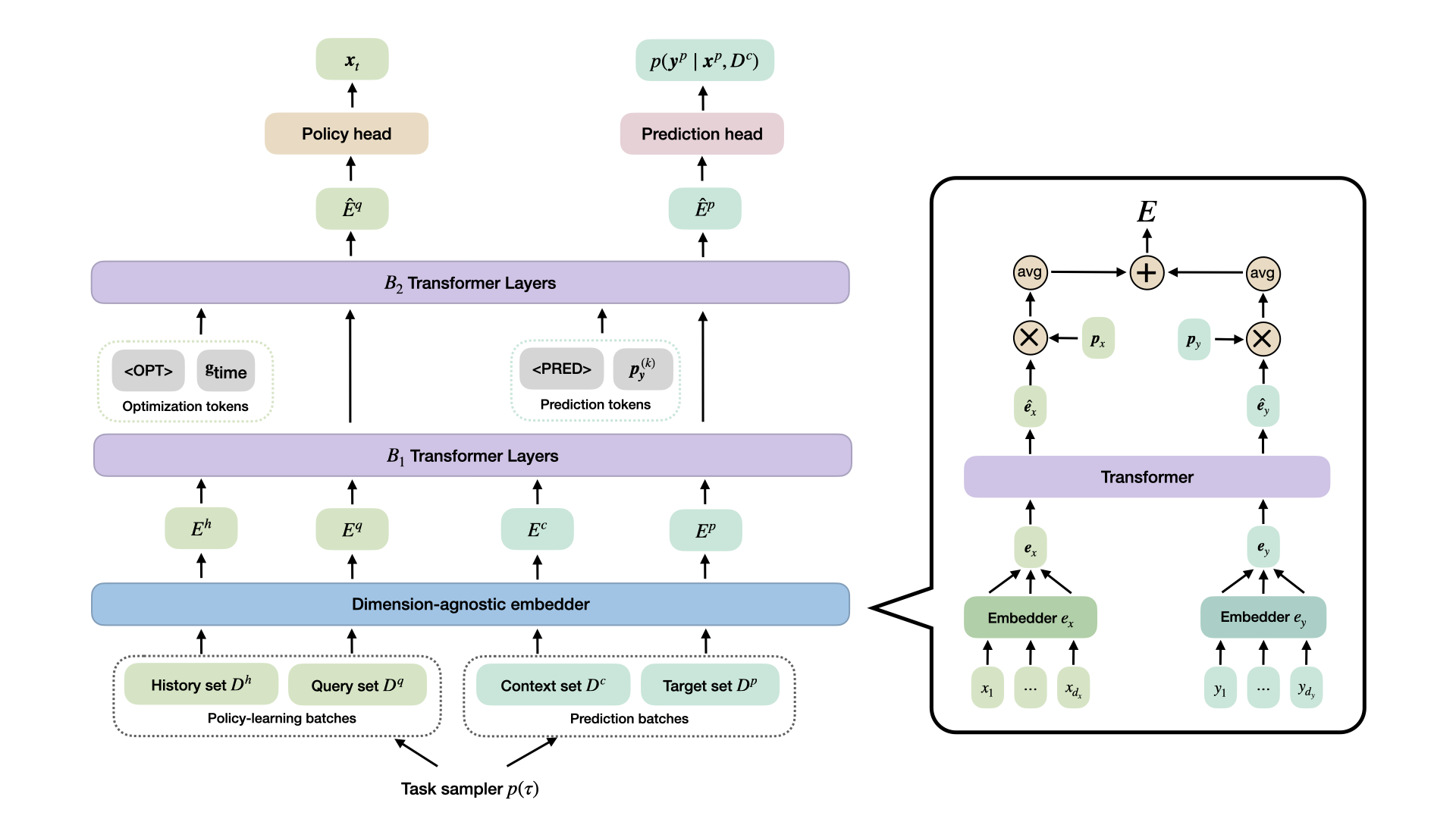
Pretraining
TAMO is pretrained offline on a distribution of synthetic multi-objective tasks drawn from Gaussian process priors with varied kernels, length scales, and input/output dimensionalities. Because the embedder is dimension-agnostic, a single pretraining run can draw tasks with different numbers of features and objectives.
Two training signals share the same transformer backbone:
Policy head & RL objective
The policy head assigns each candidate \(\mathbf{x}_i^{q}\) a scalar logit \(\alpha_i := \mathrm{MLP}_\theta(\hat{\mathbf{E}}_i^{q})\) and converts them to a categorical distribution over the query set:
\[ \pi_\theta\!\bigl(\mathbf{x}_i^{q}\mid t, T, \mathcal{H}_{1:t-1}\bigr) \;=\; \frac{\exp(\alpha_i)}{\displaystyle\sum_{r=1}^{N_q}\exp(\alpha_r)}. \]At each step \(t\), observing \(\mathbf{y}_t\) yields a reward equal to the normalized hypervolume level, \(r_t = \mathrm{HV}(\mathcal{P}(\mathcal{D}^h)\mid\mathbf{r})\,/\,\mathrm{HV}^\star_\tau\). The policy maximizes the expected discounted return over full trajectories,
\[ J(\theta) \;=\; \mathbb{E}_{\tau\sim p(\tau)}\!\left[ \mathbb{E}_{\pi_\theta}\!\left[\sum_{t=1}^{T} \gamma^{t-1} r_t\right] \right], \]estimated with REINFORCE. Training on complete trajectories encourages non-myopic, long-horizon Pareto improvement — in contrast to standard one-step acquisitions.
Prediction head & auxiliary objective
The prediction head models each scalar objective \(y_{i,k}^{p}\) as a \(K\)-component Gaussian mixture conditioned on a context set \(\mathcal{D}^c\):
\[ p\!\left(y_{i,k}^{p}\mid\mathbf{x}_i^{p},\mathcal{D}^{c}\right) \;=\; \sum_{\ell=1}^{K} \phi_{i\ell}\,\mathcal{N}\!\bigl(y_{i,k}^{p};\,\mu_{i\ell},\,\sigma_{i\ell}^{2}\bigr). \]This in-context regression task is trained by minimizing the negative log-likelihood:
\[ \mathcal{L}^{(p)}(\theta) \;=\; -\,\mathbb{E}_{\tau\sim p(\tau)}\!\left[ \frac{1}{N_p\, d_y^\tau} \sum_{i=1}^{N_p}\sum_{k=1}^{d_y^\tau} \log p\!\left(y_{i,k}^{p}\mid\mathbf{x}_i^{p},\mathcal{D}^{c}\right) \right]. \]This auxiliary task regularizes the shared representations and stabilizes policy learning.
Combined objective
The two losses are combined into a single objective, optimized jointly after an initial prediction warm-up phase:
\[ \mathcal{L}(\theta) \;=\; \lambda_p\,\mathcal{L}^{(p)}(\theta) + \mathcal{L}^{(\mathrm{rl})}(\theta), \qquad \mathcal{L}^{(\mathrm{rl})}(\theta) = -J(\theta), \]with \(\lambda_p = 1.0\) fixed across all experiments.
Results
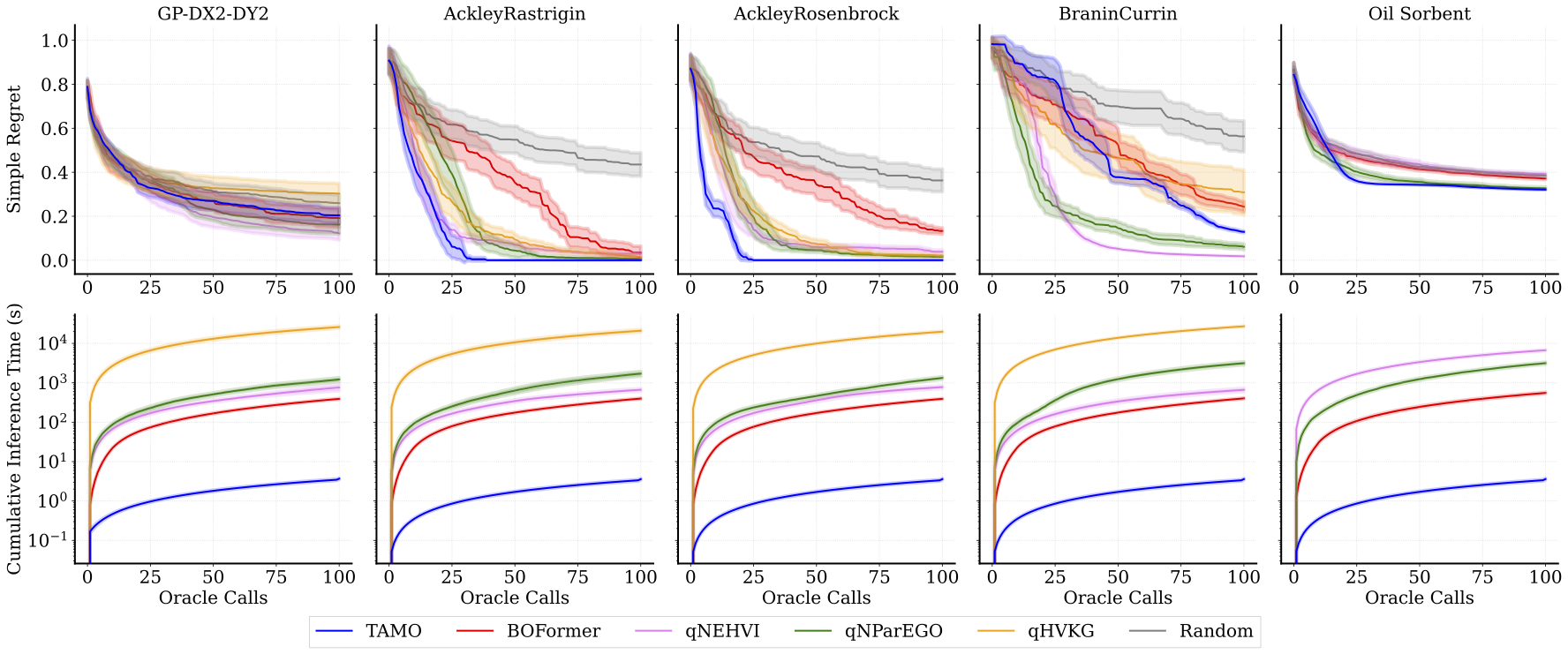
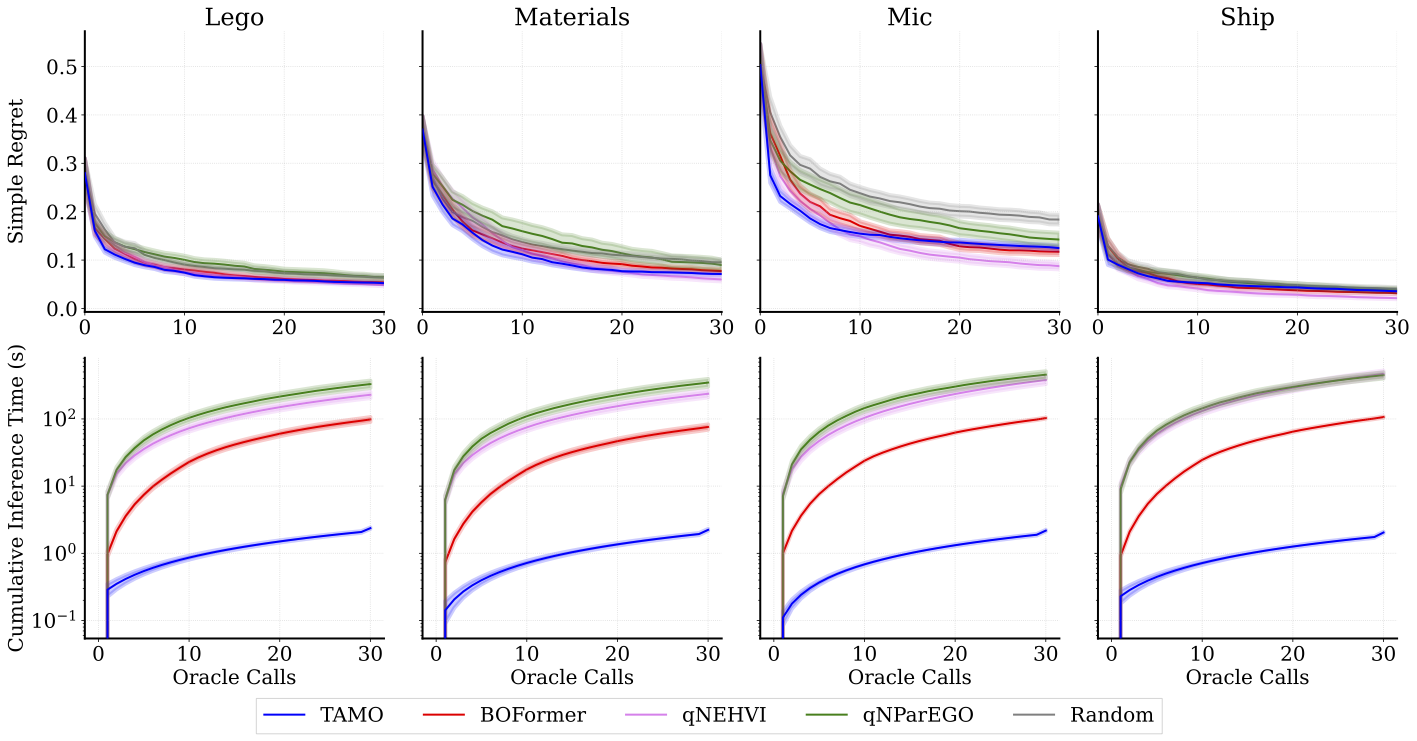
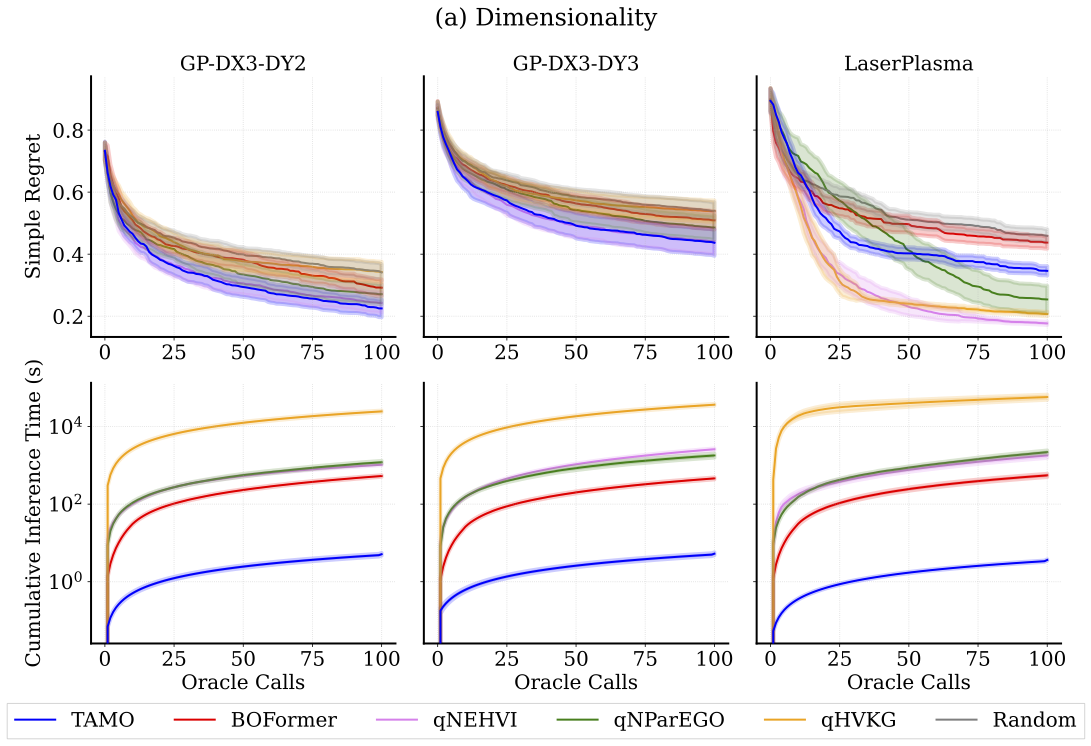
We evaluate TAMO on synthetic and real-world multi-objective benchmarks against GP-based MOBO baselines (qNEHVI, qNParEGO, qHVKG) and the amortized baseline BOFormer.
We report simple regret — how far the hypervolume of the approximated Pareto front is from the maximal hypervolume (lower is better) — and cumulative wall-clock proposal time, which for GP-based methods includes surrogate refitting and acquisition optimization at every step.
Generalization
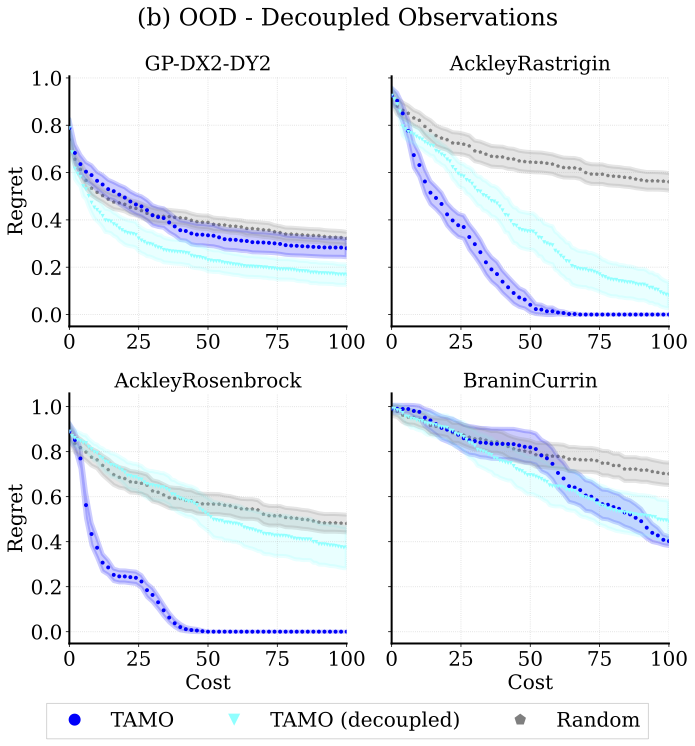
One interesting result is that one pretrained model transfers across heterogeneous problem structures with no retraining — both to unseen input dimensionalities and to settings where each objective is observed independently.
Takeaways
| Aspect | Finding |
|---|---|
| Pareto quality | Matches or beats specialized GP baselines and amortized methods on simple regret under tight evaluation budget. |
| Wall-clock speed | 50–1000× lower proposal time than GP baselines and amortized methods. |
| Synthetic-to-real transfer | Despite training only on synthetic GP priors, TAMO transfers competitively to real-world tasks — no real-data pretraining required. |
| Generalization | One pretrained model across input/output dimensions and function families. |
| Single-objective BO | Applies effortlessly to single-objective optimization, yielding competitive results against GP baselines. |
Scope & Limitations
TAMO is pretrained entirely on synthetic GP samples, which provides scale and control but may miss salient real-world structure. Performance is likely sensitive to the GP kernel family and smoothness used during pretraining. A systematic study of how corpus composition drives transfer is an important open direction.
Inference currently assumes a discrete candidate pool, which aligns well with discrete or low-dimensional design problems, but is restrictive in high-dimensional or generative settings, such as de novo molecular design. Extending TAMO to continuous proposal mechanisms (e.g., diffusion-based or autoregressive generators) is a natural next step.
BibTeX
@inproceedings{
zhang2026incontext,
title={In-Context Multi-Objective Optimization},
author={Xinyu Zhang and Conor Hassan and Julien Martinelli and Daolang Huang and Samuel Kaski},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=odmeUlWta8}
}